
In This Article
If you do a quick search for ‘automated keyword research’, there are plenty of blog posts talking about it. What most of them don’t talk about, however, is automating good quality keyword research, that can be used right off the bat, without any complicated process to follow. That’s what this post is about – a practical, scalable solution designed to take you from zero to insight, fast.
Whether you’re refining your SEO strategy, powering paid search activity, or creating content at scale, the approach outlined here is built to work straight out of the box.
Introducing Keyword Harvester
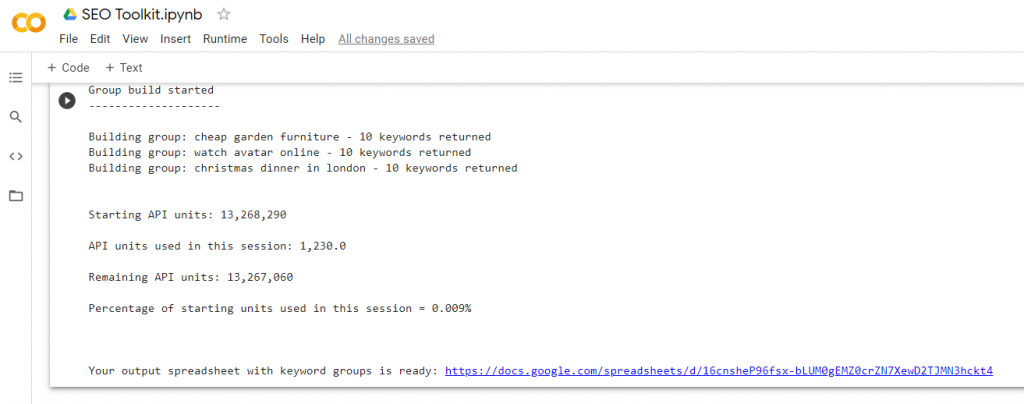
Keyword harvester is a tool that automates keyword research by working through a list of seed keywords, getting closely related keywords and search volumes for each of these – or in other words, automatically building out good quality keyword groups for them. This means there is no need to pull the keywords manually. The keyword inputs and outputs are handled directly within the fast and responsive Google Sheets interface.
It saves time and effort when doing keyword research:
- No need to manage .csv exports and imports
- No more waiting for SEO tool interfaces to load
- Freedom from two factor authentication delays
Keyword Harvester runs from a Google Colab notebook built to automate keyword research by harnessing the SemRush API with the Python-Semrush python module.
Efficient keyword harvesting
Back in the 1100s, farmers using the heavy plough could expect to harvest 250 kilos of grain from an acre of land. With its ability to turn over the fertile clay laden soils of northern europe at unprecedented speed by leveraging the automated power of the ox, the medieval heavy plough was praised as a high technology of its time. Alexander Nequam, Abbot of Cirencester Abbey, called it ‘a divine piece of work, whose utility transcends the power of writing to express’.

Thanks to the heavy plough, efficiency was on the increase, but few could dream of what would one day become possible. Today, a farmer working the same land can expect to harvest 3,500 kilos of wheat per acre – that’s 14 times as much.

Keywords are the staple grain of search, so harvesting keywords is a pretty important and commonplace daily activity for the team at Found. Up until now, it’s been necessary to find keywords by ploughing through the web interfaces of the major keyword research tools such as Google Ads Keyword Planner, SemRush and Ahrefs, for which 2-factor authentication, slow web page loads, and the management of .csv exports are part and parcel. Switch-tasking and delays such as these not only take time but disrupt focus and flow.
Conversion focused keyword research
Keyword Harvester is first designed to speed up conversion focused keyword research, which is the most common form of keyword research we do for our clients. By this, I mean research where I only want keywords searched by people who are definitely interested in a specific topic. So for the topic ‘christmas dinner in london’, I want keywords like ‘best christmas dinner in london’ but not ‘christmas dinner menu’ which is related but not closely.
Getting this tightly focused keyword research from the interfaces of the major keyword tools is fiddly and settings intensive. I have found that third party keyword research tools’ related keywords functions within the interface tend to return a high proportion of keywords which are only broadly relevant for any input phrase if I just put in that phrase on its own. They usually have functions for narrowing down by only including certain words, but these are not as powerful or easy to use as they should be. If I could get a list of just closely related keywords automatically, I wouldn’t need to spend time going through and separating the wheat from the chaff. Keyword Harvester makes this possible.
About Keyword Harvester
Keyword Harvester is part of a Colab notebook I built to do automated keyword research without having to go into a third party tool interface and wait for it to load.
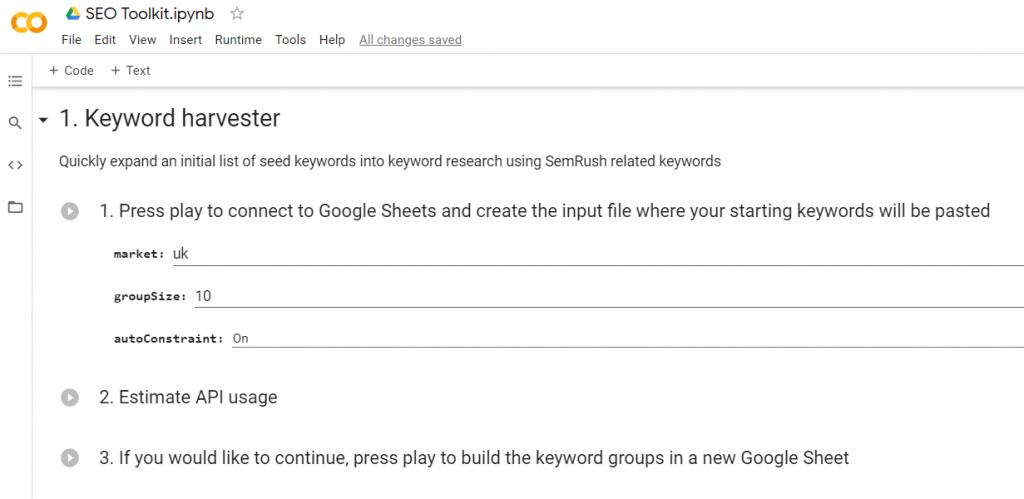
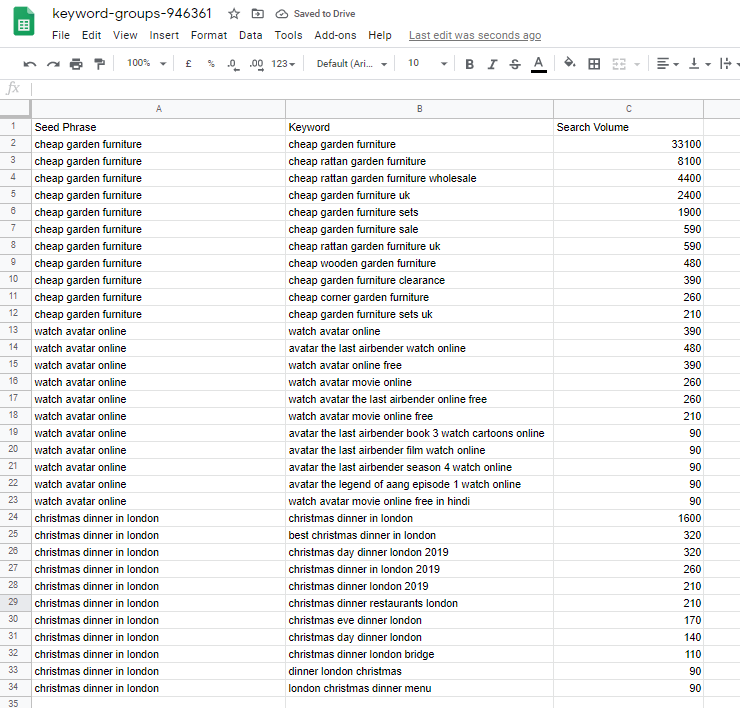
I give it a list of seed phrases and it gets closely related keywords for each one, along with the search volume. It takes one second per seed phrase. It gives me a sheet with these columns:
- Seed Phrase
- Keyword (closely related to the phrase)
- Search Volume in a specified market.
What is a Google Colab Notebook?
A place to run code in the cloud, with simple ways to input data for processing and export it for use. I put something into it like keywords or urls, either directly into a text form, or from a Google Sheet, press Play, and it runs code I put there earlier on whatever data I have input. Then it makes a new Google Sheet and puts the results of applying that code to my input data in the sheet.
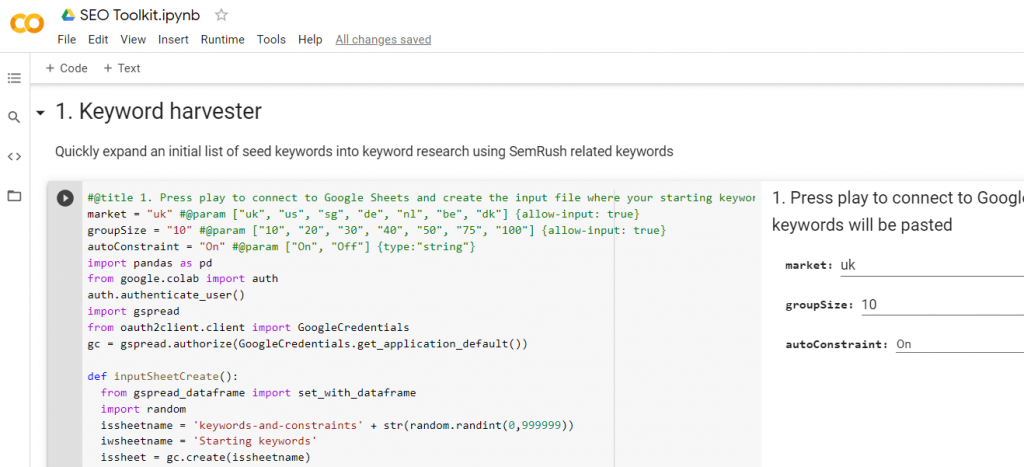
- Go to the notebook (it has a link, just like a Google Sheet)
- Authenticate by copy pasting a code
- Press play going through each step
Using Keyword Harvester to automate research
Step by step guide:
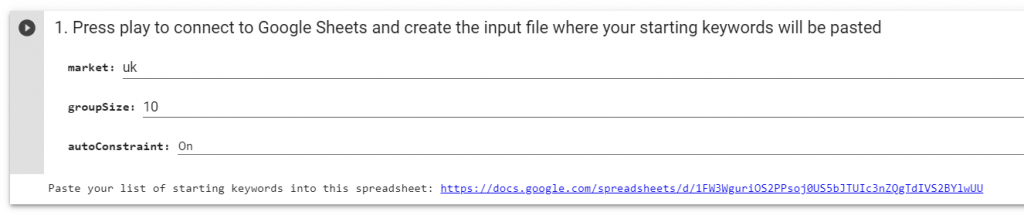
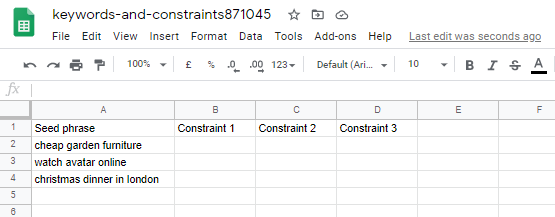
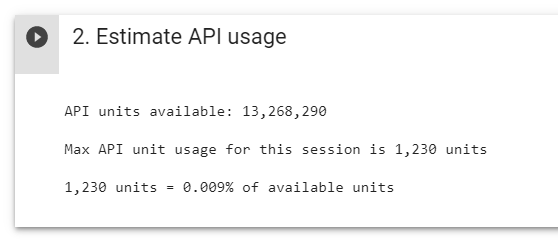
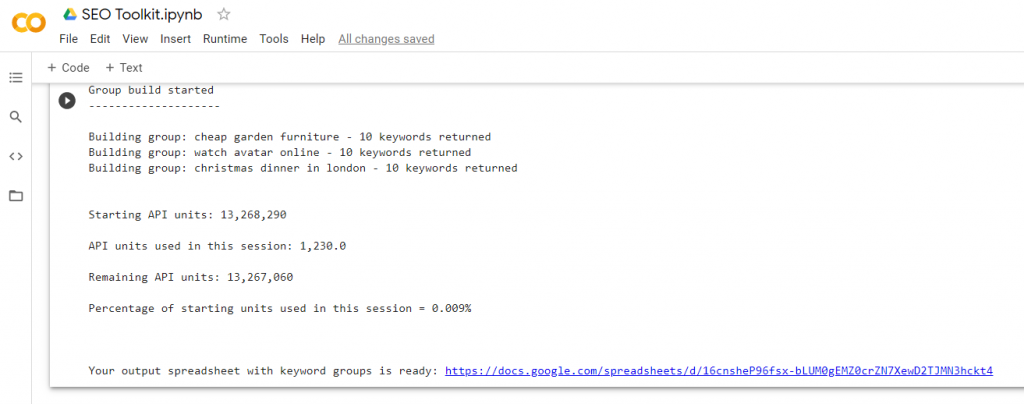
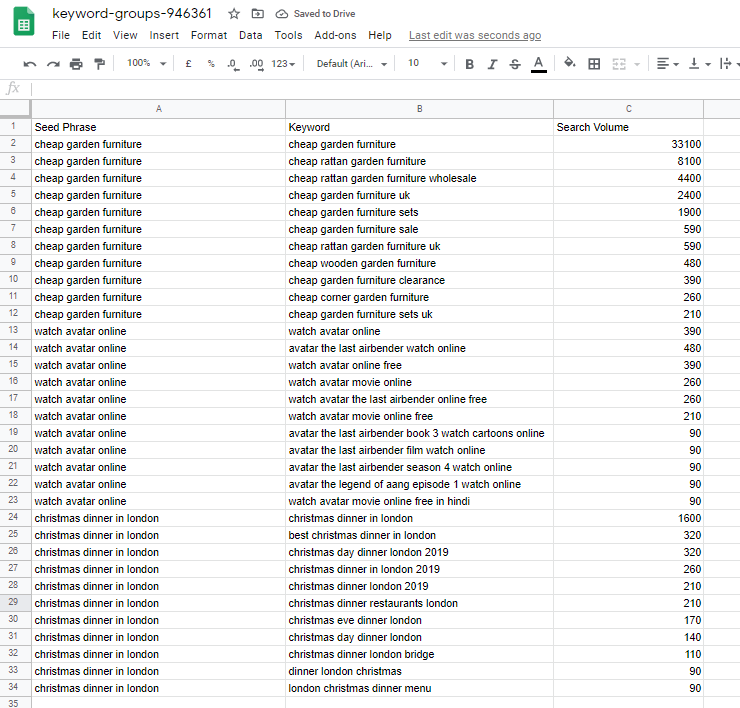
The API
Behind a keyword research tool like semrush is a series of tables with data. When you log into SemRush and research keywords, the SemRush webpage is making calls to these tables and they are sending back what is being asked for and displaying it. An API call is just like that, except you don’t have to be on the SemRush page, you can do it from anywhere.
Keyword research use case: A trip to the city
Our client, a farmer, has become so successful that they are expanding into the luxury hotel business. They want to understand the conversion opportunity around luxury hotels in london. That is the seed phrase.

To approach this, I would like to first know how many people search for keywords directly on this topic. I need a clean list of keywords that are strictly about the topic in question, and their search volumes for the relevant market. On being fed this phrase for the UK market, SemRush’s related keywords database returns the following:
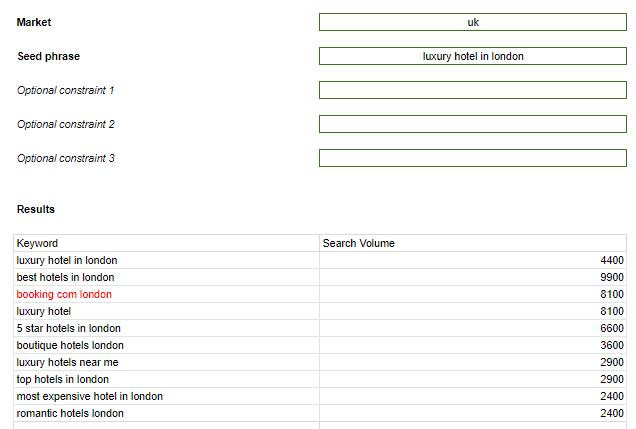
What is first apparent is that several of the keywords returned do not contain ‘luxury’ or ‘london’ even through the seed phrase was ‘luxury hotel in london’, such as ‘booking com london’. This has happened because SemRush does not know that we are conducting conversion focused keyword research. These are all related keywords, and sometimes, getting a list of keywords which are broadly relevant to the seed phrase is useful, such as when gathering content ideas for high funnel awareness building activity. But for our purposes of performing conversion focused keyword research, we need tightly related keywords to answer our specific need to find out how many people are interested in staying in a luxury hotel in london. To get this, we will use constraints – specified words which must be included in all related keywords returned.
Constraints are generated automatically to refine the keywords
There is a function in Keyword Harvester called autoconstraint, which makes it possible to do automated keyword research that’s narrowly related to a topic. When on, it will guess the constraints (the include-words to specify to SEMRush) by parsing up the seed phrases and including each one in the API call. It makes things a lot quicker, but they can still be added manually for that extra level of precision.
Back to the use case. For starters, I only want keywords about hotels! So that will be my first constraint.
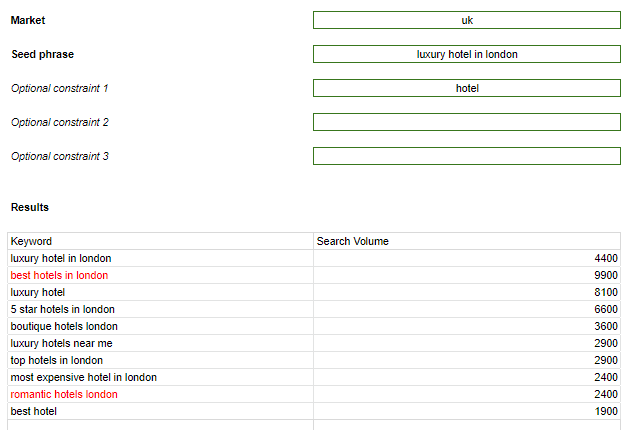
That made things better. But ‘luxury’ isn’t included in several of the keywords. This will be the second constraint.
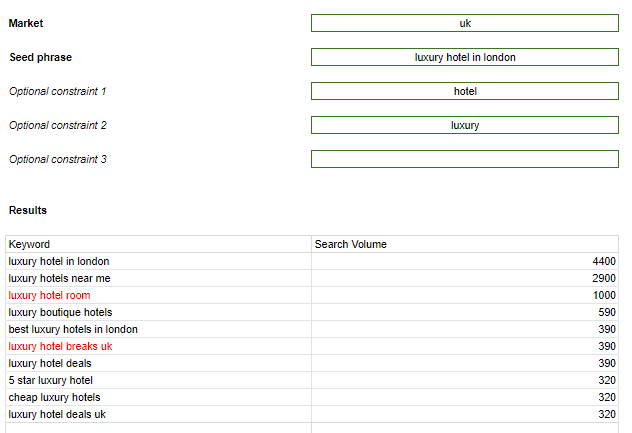
Better, but we’re not there yet. I would like to only have keywords which specify ‘london’ (Google’s searcher location detection for generics notwithstanding, for the purposes of example):
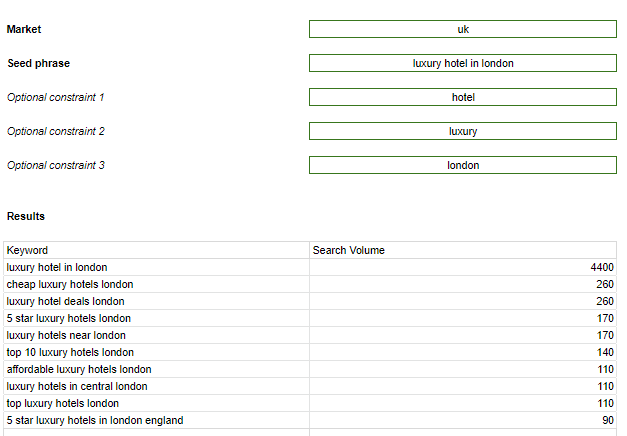
That’s more like it! That’s just for one seed phrase. I can feed in multiple phrases and this process will be automatically applied.
- Time elapsed: < 1 minute
- Mental state: Unrattled
- Focus of mind: ‘How can this information be used to achieve our objectives?’ rather than ‘Why is this tool so slow’
The Technology behind Keyword Harvester
The SemRush API reports ‘phrase_this’ and ‘phrase_related’ are called from Google Colab using the python-semrush package, with the request parameters modified to reference the user input values for the seed phrase, market and constraint parameters. The data is transformed in Pandas and is read from / written to Google Sheets with Gspread.
Outcome: More Freedom
By allowing for better field drainage, access to the most fertile soils, and saving of labor time, the medieval heavy plough stimulated food production and, as a consequence, population growth, specialization of function, urbanization, and the growth of leisure. It made a lot of people more free to do other things.
Using Keyword Harvester to automate my keyword research has saved me time by taking the friction out of the soil, thanks to the versatility of the SemRush API and the speed and simplicity of Google Colab.

Found is a London-based multi-award-winning SEO, PPC, Social and Digital PR agency that harnesses the efficiencies of data and technology and future-thinking to help clients grow their businesses online.

