
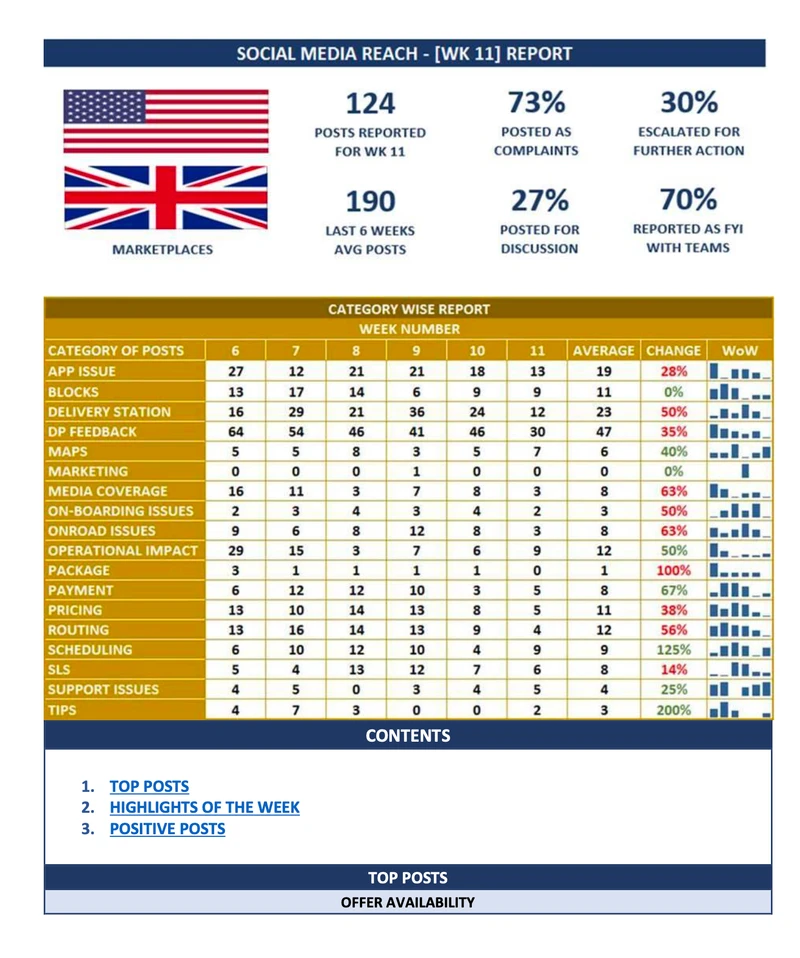
How Data Science Boosts Marketing?
We might one day “become less valuable than the data we produce,” the opening scene from Watchdogs 2. Giving away our freedom to tech companies without even knowing it is a scary prospect. In simple terms it would mean being rejected from a mortgage before you’ve even applied based on the huge amounts of data being siphoned from you.
We haven’t arrived at that scary future yet, pray we never will. Nevertheless, the already staggering amount of information available to marketers is a gold mine for data scientists. Traditional advertisers have been driven by gut feelings. Data scientists’ gut feelings are hypotheses: hunches about untapped veins in mountains of messy data.
A good marketing data scientist should be an adept engineer capable of cracking the vault of online data through APIs and large-scale scrapes and be able to persist that data in a robust way. They also need to be able to tell a story through data by playing the curious investigator, knowing which tools to apply and how to string together a narrative of actionable insight. Commercial awareness is everything – context is the difference between a party factoid and a relevant, applicable insight to drive forward a marketing strategy. Research, experiment, influence, attribute and optimise.
This article describes a handful of approaches that use data science to huge effect in various digital marketing streams.
Trust Issues with Attribution
Yes, yes attribution. The only way to know the full truth behind the performance of marketing strategies yet paradoxically not for everybody. Partly to do with data scientists’ inability to reverse engineer conclusions about attributed revenue figures. We as data scientists know exactly the process raw data is churned through to output the report numbers but building confidence in this insight requires explainability. Clients shouldn’t be expected to take the data scientist’s word on why channel X is more effective than channel Y; data scientists should be accountable for their results. Faith cannot be a component of any data-driven strategy.
Attribution tells us what works and it allows marketers to optimise their budgets more effectively. It’s all about the ROI. Knowing one campaign has a strong indirect halo effect across several channels is a powerful insight that allows marketers to optimise their budgets a lot more intelligently.
Customer Persona Development & Audience Mining
Social media mining (SMM) is the art of sifting through masses of unstructured data from social media platforms. It is a highly challenging task and generating insight beyond bog-standard sentiment time series graphs can be a true art form. Social media offers a sympathetic ear into niche communities defined by highly specific interests that can tell companies a lot about their customers. Generally speaking, SMM is ideal for conducting market research, tracking campaigns, audience persona research, understanding product contentions and monitoring brand awareness. Be warned though, it is also residence to mass marketers, spammers, trolls, spies and hackers.
This is a good time to talk about good and bad social listening. There is so much bad social listening.

A team of social miners at Amazon were recently exposed for their internal web tool designed to spy on their Amazon Flex drivers. Honestly, the organisation of it was highly impressive but overall tremendously unethical. The ne’er-do-wells receive real-time updates and analysis on their drivers’ social media posts across closed Facebook groups, Subreddits, Twitter pages and other websites with the intention of predicting and escalating strike action and other behaviours that might disrupt their regime, adding a splash of realism to the prospect of applications being rejected before even being written. The automated tool is not restricted to internal operations either. These drivers are not Amazon employees. They are independent contractors with their own vehicles and no company benefits.
With the PSA out of the way, social media listening is a powerful tool for surfacing insights about your target audience. The practice is generally executed in two waves: (1) data collection and (2) data analysis. Neither are straightforward procedures. Data collection requires a lot of careful forethought and experimentation to ensure that the primary data source contains quality relevant information for analysis. Analysis is arguably even more difficult but done well can yield very compelling insights. The following analysis framework can be a helpful tool for structuring an investigation of the social web.
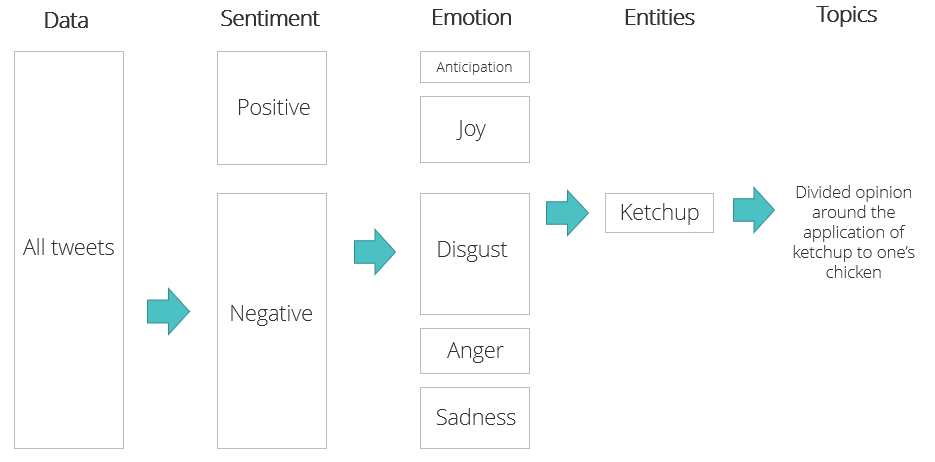
There are a number of products available that help with social listening, such as Notifier for Reddit, which can alert you whenever your brand or keywords are mentioned on Reddit and even help you find new customers. If you’re on a budget however and want free access to raw social data, then the Twitter API is probably the most accessible entry point. It allows developers to programmatically search through Tweets for relevant statuses. A quick and simple base is to start by separating statuses between those expressing negativity and those expounding positivity. From here, we can use data science to split text documents into different categories of emotion: angry tweets expressing outrage, tweets expressing elation and joy etc. From emotions we can use topic and entity analyses to extract hot themes and topics of conversation. We applied the above example to Nando’s audience and found a segment of users expressing disgust centred around guests slathering their cheeky chicken in ketchup rather than their painstakingly crafted Peri Peri specialties. The analysis unearthed a highly divisive topic likely to generate strong engagement through content.
One last tip. If it seems like you’re being deceitful then you probably are. Is it a world you want to help create?
Hand to the King: Data-Led Creative
Knowing who will engage with your content and how they might react is key to claiming the content throne. Data science can be applied to determine the linguistic habits and idiosyncrasies of your audience as well as their visceral reactions to different brands and topics, which will inform on how to speak to your audience and how they might react. The point isn’t to create creepy content, it’s generally to make your (capitalist) life better.
This might mean common phrases and language, how well content that provokes emotion engages an audience and the overall relationship between emotional arousal and attention. Think YouTube comments section sans troll. Emotions in language can be measured three ways:
- Emotional content: the types of emotions conveyed in language and how much of a piece of text is emotional
- Affect intensity: The intensity of the emotional content, for example “evil” is more intense than “naughty”
- VAD: The valence (dis/pleasure), arousal (active/calm) and dominance (full/no control or powerful/weak)
Knowing what sort of content to produce is one challenge but measuring the success of that content is another. It is difficult trying to evaluate content success from Google Analytics staples, traffic and time on page. This forces data scientists to get creative with creative. It is why development is underway here at Found to build a platform to this end, engineering new lenses to assess content.
Get Smart About Keyword Research
An early step in building a SEM strategy is keyword research. For biddable media, this requires keywords being hierarchically clustered into an “account > campaign > ad group > keyword set” ad structure. SEO clusters are less rigidly defined across the industry but often adhere to something similar.
Grouping a few hundred keywords is not terribly difficult. Scaling this process by several orders of magnitude higher negatively skews the balance between hours spent researching a strategy and its payoff.
But – there is an inherent structure in unstructured data. Uncovering this structure is the key to automating the process. That, and a bunch of API integrations (which a data engineer could easily take care of). Clustering is an ancient technique bestowed to data scientists developed by anthropologists in the 1930s. It’s simply a set of algorithms to group things that are similar to each other and if performed carefully can take care of up to 80% of the work of structuring a raw keyword set. From there, keyword prioritisation is only logical.

20th Century Ideas, 21st Century Technology.
Customer lifetime value, predicting churn, customer segmentation.
Et cetera.
But using machine learning data scientists can process more data, generate more accurate predictive models. You get the idea, let’s not labour the point. Just think of a classical marketing problem and give it to your data scientist.
Predictive Lead Scoring
Selling a B2B service is hard work. Conversion rate in B2B marketing is only meaningful insofar as the leads generated are qualified inquiries. B2B enterprises often struggle with lower site conversion rates because conversions come from a much smaller sub-population of senior decision makers front-loading a considerable amount of research and comparison before the final form submission.
There is also a fine balance at play in sending more traffic to the site and sending the right traffic to the site. Lead scoring is a classic marketing automation task designed to target the right customers and prospects. The idea is for machine learning models to learn from the behaviours and attributes of existing users and prospects against a scale that distinguishes those more likely to convert. It provides a traceable metric to point marketers in the direction of valuable customers and allows them to run highly targeted campaigns.

Discover practical ways data science can transform your marketing and see how Found’s expert team can help you turn insights into real impact.

