
In a world where we are always checking the news for the latest stories, publications are under a lot of pressure to create new articles that will bring readers in every day. Unfortunately, this pressure to produce can lead to misunderstandings or flawed reasoning when taking information from search results in many articles. Writers can draw invalid conclusions from extrapolated data which doesn’t actually show what they think it does. Basically, writing about search can go wrong if you don’t do your research.
The frenzied media coverage over the U.S. election and the “Brexit” vote has thrown up several instances of how publications get search wrong. Below we look at a few of them, including the infamous SourceFed video that mistakenly claimed Google was manipulating search results for Hillary Clinton, and the googling Brexit non-story that whipped up controversy when there was nothing to substantiate it. We also look at how publications can hopefully avoid making these errors again because guys, seriously, there’s enough nonsense on the web as it is without serious writers contributing to it.
The Brexit fiasco
Or…misunderstanding how Google Trends works
Following the UK’s vote to leave the EU on June 23rd 2016, several American news organisations erroneously reported that there had been a spike in searches for “What is the EU” made in the UK, after the referendum. This then implied that many people had cast their votes without knowing what they were actually voting for or against, causing further controversy around the issue.
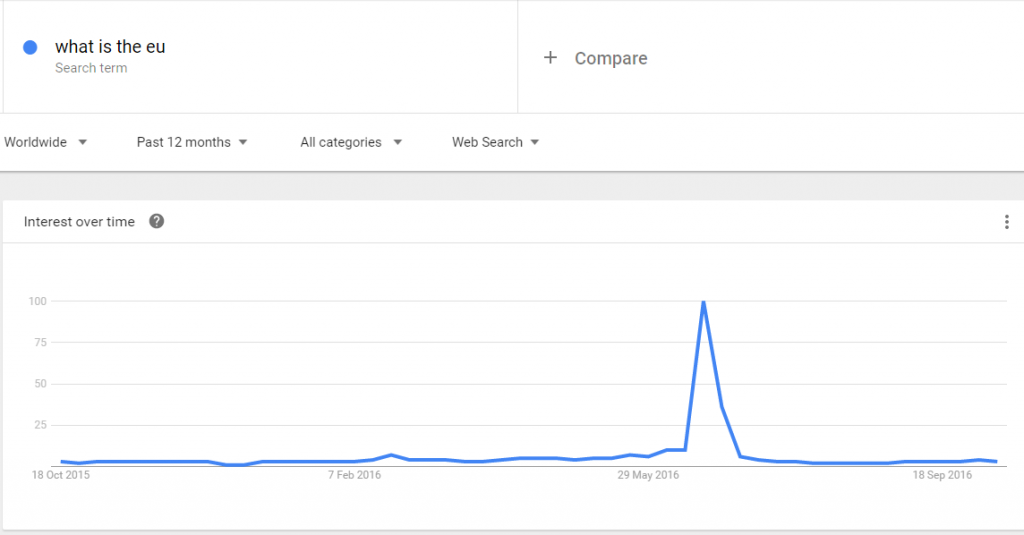
The data that the journalists based their story on was sourced from Google Trends, but the mistake they made was in assuming that the search volume for a certain term is a definite indicator of popularity. Instead, Trends provides search numbers that are relative within a set date range and in context of other terms. It does not show exactly how many people have actually searched for something, so making assumptions on this data is pretty silly. You need to validate the numbers yourself, check other sources, and make sure you know what you are looking into.
Trends analyses a percentage of searches on Google, showing how many searches were done for a particular term over a set time period. That data is then adjusted to make comparisons easier. So you might have two different regions, the United States and the United Kingdom for example, and on Google Trends they might show the same number of searches for “What is the EU” but that doesn’t translate into them having the same search volume.
Looking at related terms could have helped to identify why “What is the EU” was trending – these results hadn’t taken into account that the term could have been modified, such as by the far more likely “What is the EU referendum result?” In fact, deeper research showed that only around 1,000 people in the UK had searched for “What is the EU?” and even then, because the data is anonymised there is no way of saying if these people were actually confused voters.
These articles and misunderstandings of data lead to huge controversy around an already touchy subject. It could have been easily avoided with some interrogation of the data; how much geopolitical information can you extract from Google Trends? In this case of supposed ignorance, not much.
How to avoid it
If you’re interested in search volume, then Google’s free Keyword Planner will give you far more accurate statistics about how many people are searching for a given term than Trends, which only gives you relative volume. You can also break the data down, such as by location or device. When using Google Trends, looking at relative terms also helps to understand the overall context of why a certain term might be trending.
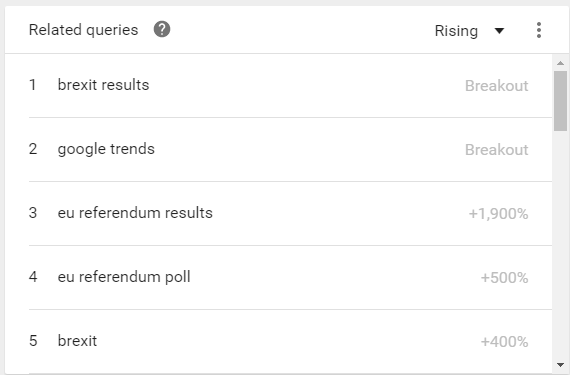
Google Trends: “What is the EU” related queries 01/05/16 – 31/08/16
The false Clinton censorship reports
Or…finding bias where there isn’t any in search results
“Google has never ever re-ranked search results on any topic (including elections) to manipulate user sentiment…” – the words of Amit Singhal, a senior Google vice president.
In June 2016 YouTube channel SourceFed released a video that claimed Google was burying negative search terms for Hillary Clinton – one example given was that typing in “Hillary Clinton cri” did not return an autocomplete suggestion for “Hillary Clinton criminal charges.” That and other allegations made in that video rapidly gained traction in the media of course and were also picked up by Donald Trump’s campaign team. But by the looks of things, they’re entirely without merit.
Yet it did look as though autocomplete had been manipulated, or censored if you prefer that term, to a certain extent to show only “good” results. The question is why.
Google has said that it removes certain suggestions to avoid causing offence to people unnecessarily. So there’s nothing preventing you from searching for “Hillary Clinton criminal charges” and getting a list of relevant results. It’s just that Google is not inclined to suggest you go looking for them. And the exact same goes for Trump. Search for “Donald Trump ra” and you’ll get suggestions such as “rally,” “ratings” and even “raw,” but not the big issue that’s been on everyone’s lips for the last few weeks.
This might be because Google wanted to avoid unnecessary legal complications such as the controversial “Right to be forgotten” law, or it could be it sticking with Alphabet’s “Do the right thing” corporate motto, but conspiracy? Nah.
Here’s the thing – search is for the most part totally run by algorithms, but there is probably a human who is choosing which negative search terms to filter out. It is possible that some bias could slip in there, but there is no, repeat no evidence that that has ever been the case, only some conjecture.
How to avoid it
Look beyond the easy explanation that there is something sinister going on. Instead, consider the real reasons why Google might be self-censoring. If you’re looking for information on a particular topic, search for the whole term rather than relying on autocomplete.
Whatever term you search for, Google will give you the best, most relevant information, so rather than saying “oh, that is really topical but not showing up straight away” search for the whole phrase and analyse the actual search results.
Personalisation of search results
Another aspect some journalists tend to forget is that search results are personalised. No-one sees the identical set of results for a set term. They can be skewed by where you are in the world, down to a country or a local level; your personal search history; your activity on other Google-owned platforms such as Gmail, Drive or YouTube. Failing to appreciate how the SERPs can be skewed in this manner can again lead to misjudged conclusions.
How to avoid it
Before searching, clear your cookies, browser cache and history. Turn off your location data and log out of all your Google accounts. Alternatively, try searching with a different browser to the one you normally use, or search incognito. This will make sure that you have the least personalised results possible, meaning you should get a “truer” picture of what the SERPs actually look like for your queries.
Adding to the complexity of search is the fact that it is constantly evolving. Google has not been top of the heap for this long without improving this as often as possible. It’s inevitable that publications will make errors when basing stories on search, but by gaining a firm grasp of how the different search tools work, and why they are designed to work in that particular way, these issues can hopefully be avoided.
Research everything thoroughly before you publish it and do some background reading on interpreting information supplied by Google to make sure you know exactly what to look out for.

