
Crawl budget & log file analysis
Google is constantly crawling the web to index new content and any changes made to existing content. The perfect scenario once Google has crawled your site, is that every crawl results in all SERP (search engine results page) worthy pages being crawled and indexed. Unfortunately for SEOs and webmasters worldwide, this is not the case. Google actually limits the number of pages it will visit, this is known as crawl budget. So, you might be wondering two things at this point.
1) How is crawl budget assigned? And
2) How do I increase my crawl budget?
Crawl budget
Crawl budget is assigned based on a site’s authority. The formula is simple; the higher your site authority, the more URLs Google will crawl. Due to their high authority these sites are referenced multiple times across the web, therefore it can be presumed they will contain relevant and engaging content valuable to it’s users. For this reason, it’s in Google’s interest to ensure the results pages are constantly updated with any new pages added to a high authority site and any changes made to existing content.
So, to increase a site’s crawl budget you’ll need to increase site authority. SEO link earning practices seek to do this by gaining relevant links from other authoritative sites. However this is a timely process so whilst site authority is being built there are quicker wins to be had. Outside of increasing your crawl budget you can optimise the way your site is crawled. The best way to do this is to analyse your log files and arrange actions off the back of this.
Log files
Log files are recorded on a site’s server and allow those with access to see how users and bots are interacting with the URLs on the site. In its raw form, the data can look a little daunting…
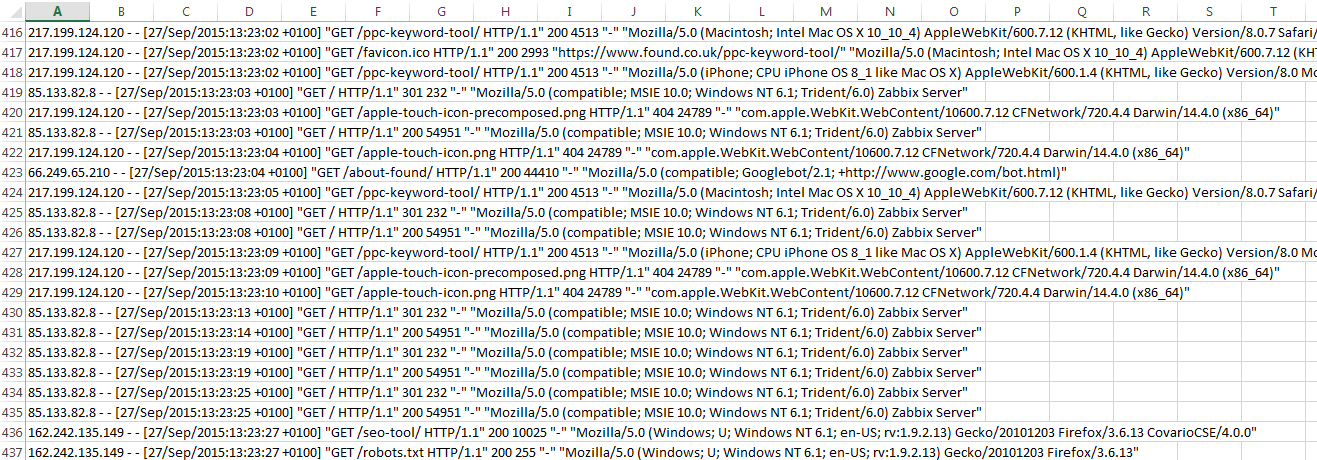
However, an understanding of the data segments within the file and a quick filter on the columns feature in your spreadsheet turns the data into a valuable resource for analysing your site’s crawl ability.
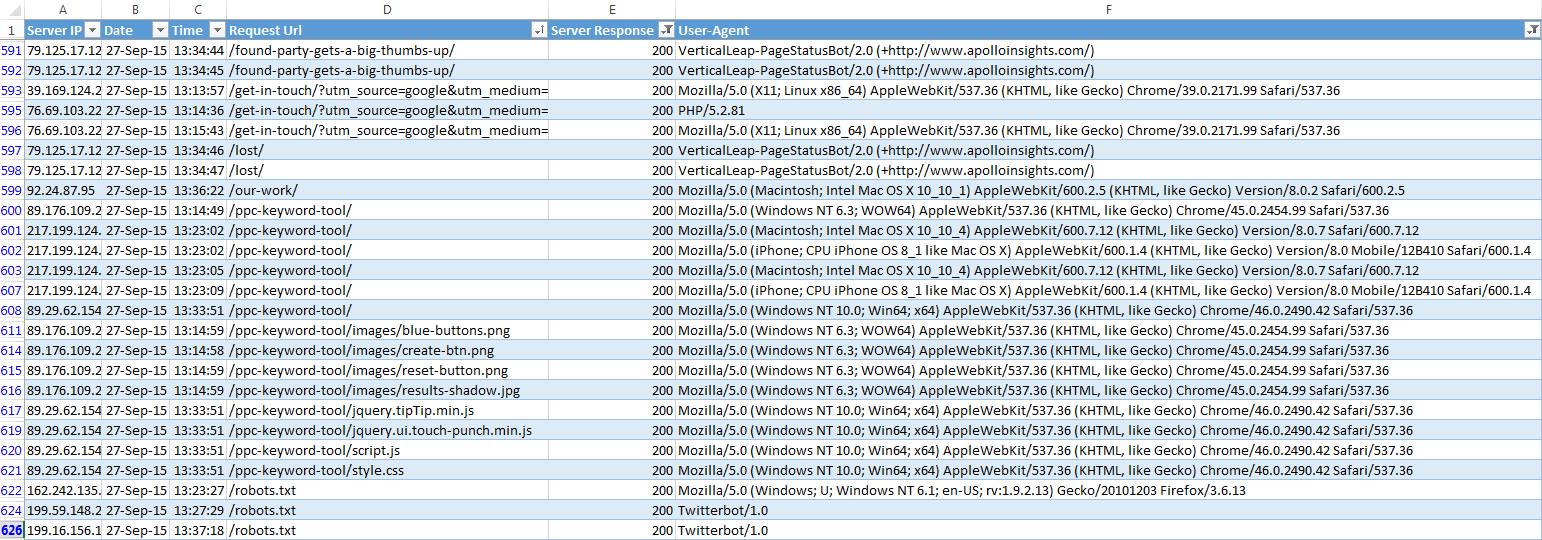
The information shown above has been split into the following sections:
- Server IP – The IP address of the bot or user accessing a file on your site
- The date the URL was accessed
- The time the URL was accessed
- The URL requested by the agent
- Server response – The HTTP response status code of the requested document
- User-agent – The declared name of the browser or spider accessing the URL e.g. Firefox, Googlebot etc.
Log file analysis
Implementations off the back of log file analysis have the opportunity for massive impact. Whilst crawl inefficiencies may not have a direct negative impact on rankings, improving the number of important URLs crawled means your content will be indexed and updated more frequently. Both of which are factors in earning and retaining strong rankings.
Once the data has been segmented correctly you can begin to analyse where crawl budget is being wasted. Firstly, look to restrict data to only showing Googlebot data, then search for URLs within the data set that you do not want to rank.
Common examples of these include the following:
404s
The server response column lets us know just how many 404 error pages are being found within a crawl. A small number of these will be found on every site and generally won’t be harmful to a site’s organic visibility, but once larger numbers of 404s begin appearing, further analysis is needed.
Using a tool like Screaming Frog can help you to assess the number and cause of 404 errors on the site.
Parameter URLs
Ecommerce sites commonly use parameter URLs to serve visitors filtered or condensed content. Allowing these to be crawled can mean a large percentage of crawl budget is wasted on these URL types and allowing them to be indexed can cause even more serious duplicate content issues.
Google Search Console provides a list of parameters currently recognised by Google for your site. Creating a pivot table within the log file analysis and filtering by these parameters/ using COUNTIF formulas highlights how many of these URLs are being crawled. If any parameter has a high number of crawls it’s down to the analyst to determine whether or not these URLs need to be crawled and take action to stop this. This may involve editing of the robots.txt file or blocking the parameters within Search Console.
This is only a very brief look into what can be achieved with log file analysis and increasing crawl budget. As a task that has the potential to improve the way your site is crawled, it should be a top priority, especially for large sites which have a high propensity to be wasting crawl budget on unnecessary pages.

If you need help with log file analysis, our SEO team is here to assist providing expert guidance.

